
Best Machine Learning Model for Sparse Data in 2023
A dataset with a significant percentage of zero or null values is considered sparse. Sparse datasets with high zero values can cause overfitting in machine learning models, among other issues. Sparsity in the dataset is typically not a good match for machine learning applications, so it should be avoided.
Sparse data lacks the actual values of features, and missing data contains null values. Dealing with sparse data is thus one of the most challenging aspects of machine learning. In other situations, dataset sparsity is still beneficial because it enables faster deep-learning network training and a smaller memory footprint for traditional networks on mobile devices.
So, in this article, we will talk about the machine learning model that would be helpful with sparse data. So, let’s get started without wasting any time.
Table of Contents
Numerous issues with sparse datasets arise when training machine learning models. It is necessary to handle sparse data carefully due to the problem. The following are typical issues with sparse data:
Different Methods of Handling Sparse Datasets For Machine Learning
As was previously mentioned, sparse datasets are ineffective for training a machine learning model and should be handled carefully. There are numerous approaches for dealing with sparse datasets.
1. Change the Thick Attribute to Sparse
A dataset’s sparse data should be transformed into dense features. Machine learning models are typically trained on dense feature datasets. The feature density can be increased using a variety of techniques, such as:
- Utilize a low-variance filter.
- Analysis of Principle Components in Practice.
- It is necessary to perform feature extraction and selection.
- Implement Feature Hashing.
- Utilizing t-SNE, or t-Distributed Stochastic Neighbor Embedding
2. K Nearest Neighbors (KNN)

The entire training dataset is used as the model representation for KNN. The KNN method is simple and effective. KNN may require a lot of memory or storage space to save all the data, but it only calculates (or learns) when a prediction is required, just in time. Every time a new data point is added, the output variable is summed for the K neighbors most similar to it in the training set. It suggests concentrating solely on the input variables necessary for predicting output variables.
The idea of distance or proximity can lose meaning in situations with many variables (high dimensions), which could negatively impact how well the algorithm completes your challenge. The “dimensionality plague” is a term used to describe this. This could be the mean output variable in a regression problem or the modal class value (or most common class value) in a classification problem.
It takes time and effort to understand how similar the data instances are. The Euclidean distance is the simplest method if all your features are scaled equally. Using the differences between each input variable (all in inches, for example), you can calculate the value of this distance. You can also continuously update and maintain your training instances to ensure accurate predictions.
3. Get Rid of the Model's Characteristics
It is one of the simplest and quickest ways to handle sparse datasets. Because sparse datasets might contain crucial and essential information that should be kept from the dataset to improve model training, which could harm performance or accuracy, this method involves stripping some of the dataset’s characteristics to train a model.
4. Logistic Regression
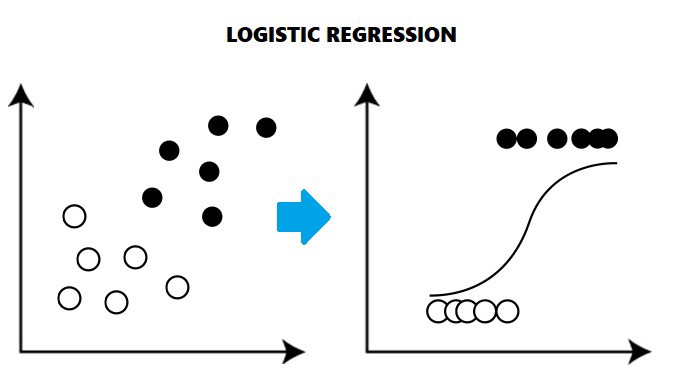
A logistic regression technique estimates discrete values from independent variables (typically binary values like 0/1). Analyzing the data and fitting it to a logistic function allows one to predict the likelihood of an event. It is also known as “logit regression.” The methods listed below are frequently used to enhance logistic regression models:
- It is a bright idea to remove features.
- The use of conversational language
- Take advantage of a non-linear model.
- It is necessary to standardize techniques.
5. Employ Unaffected Methodologies with Sparse Data
Sparse datasets do not affect the behavior of some machine learning models because they are robust to them. For instance, Normal K suggests that the method is ineffective and is constrained by sparse datasets, leading to decreased accuracy. However, sparse data have no impact on the entropy-weighted k-means method, which produces trustworthy results. This tactic can be used if there are no restrictions on using these algorithms. As a result, it can be used with sparse datasets.
6. Boosting & AdaBoost
AdaBoost was the first successful binary classification boosting technique. Modern boosting methods, most notably stochastic gradient boosting machines, are built on the AdaBoost platform. It is the best starting point for learning about boosting. Boosting is an ensemble technique for transforming ineffective classifiers into effective ones. AdaBoost is used in conjunction with short-decision trees. More weight is placed on training data that is challenging to predict, while less weight is placed on simple instances.
Sequential model development involves changing the weights on the training examples for each model, which affects how well the next tree in the sequence learns. First, a model is developed using the training data, followed by a second model that corrects the errors in the first model. The number of models is added until the training set can be accurately predicted or until the maximum number of models is reached. Predictions for new data are generated after all the trees have been built, and the performance of each tree is weighted based on how well it performed on the training data. Since the algorithm places such a high priority on error correction, it is essential to have clean data with outliers removed.
7. Support Vector Machines
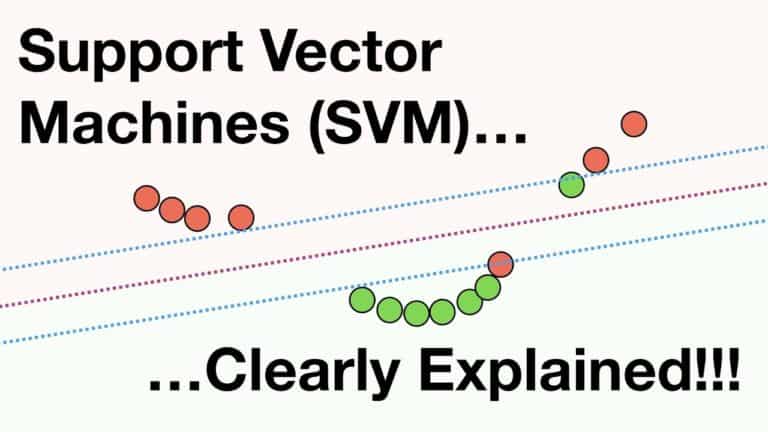
One of the most common and hotly debated machine learning techniques is support vector machines. The input variable space is divided by a path called a “hyperplane.” The SVM learning method finds the coefficients that lead to the ideal hyperplane separation of the classes. The SVM selects a hyperplane that divides the input variable space’s points into class 0 or class 1 points most effectively. Since this can be visualized as a line in two dimensions, it can completely separate each of our input points.
The coefficient values that maximize the margin are chosen using an optimization method.
It is worthwhile to test SVM on your dataset because it is one of the most effective built-in classifiers.
The distance between the closest data points and the hyperplane is known as the margin. The line with the largest significant margin is the best or ideal hyperplane to divide the two classes. Only for these locations are the hyperplane and classifier necessary. They are known as “support vectors.” They either specify the hyperplane or provide arguments in favor of it.
8. Naive Bayes algorithm
A Naive Bayesian model’s simplicity of construction and usefulness are advantageous for large datasets. A Naive Bayes classifier assumes that each feature in a class is present independently of the others. It is simple and has outperformed even the most sophisticated classification techniques. Although these characteristics are connected, a Naive Bayes classifier would look at each separately to determine the likelihood of a particular result.
The Problems of Using Sparse Data in Machine Learning

A Tight Fit
When the training dataset has too many features, the model will tend to follow each step of the training data, which will improve accuracy in the training dataset but reduce performance in the testing dataset. Although it is over-fit to the training data, the model in the previous graph tries to replicate or follow every pattern in the training data. As a result, the model’s performance on a test or anonymous data will decline.
Changes to Algorithm Behavior
Logistic regression is one technique that exhibits terrible behavior in the best fit line when trained on a space dataset. On sparse datasets, some algorithms may not perform well or may perform poorly. The performance of some algorithms degrades when trained on sparse datasets.
Space Difficulties
If the dataset has sparse characteristics, space complexity will increase because it requires more storage than dense data. Therefore, processing this type of data will require more processing power from the computer.
Difficult Timing
It will take longer to train the model when the dataset is sparse than when it is dense because the sparse dataset is more significant.
Disregarding Vital Information
Some machine learning techniques ignore the value of sparse data and train and fit models primarily on dense datasets. The method ignores the previously avoided sparse data, which may have some helpful information and training power. They need to catch up in their attempts to fit sparse datasets. Therefore, dealing with sparse datasets is only sometimes a good idea.
Frequently Asked Questions
Q. What benefits does a sparse model possess?
Sparse modeling outperforms traditional AI methodologies by providing feedback that explains its solutions’ outcomes and assumptions.
Q. What is the meaning of a sparse regression model?
A regression vector is referred to as sparse if only a portion of its components are nonzero while the remainder is zero, leading to variable selection. For instance, the model does not select the predictor variable, which is removed if j = 0.
Q. What does machine learning's sparse modeling entail?
In sparse modeling, a significant portion of the data is typically predicted to be zero. In other words, the available information is “sparse.” If you consider this shaky premise, you might get results even with scant data.
Q. How does machine learning handle sparse data?
Sparse matrices can be represented and handled using a different data structure for the sparse data. Only the data or nonzero values in the sparse matrix need to be stored or used; the zero values can be ignored.
The Final Words

Sparse data is a common problem for machine learning, especially when using a single hot encoding. It is strongly advised to handle sparse data due to the issues it can create (such as over-fitting, poor model performance, etc.), which will improve model development and machine learning model performance. It is a category of data that has a lot of zero values.
When dealing with sparse datasets, dimension reduction, making sparse features into dense features, and using sparsity-resistant techniques like entropy-weighted k means may be the solution. Care should be taken when handling sparse data to avoid problems like over-fitting, model performance degradation, and time and space complexity.


